作者
Laura Ann Garrison1; Juliane Müller2; Stefanie Schreiber2; Steffen Oeltze-Jafra2; Helwig Hauser1; Stefan Bruckner1

本文是 1University of Bergen 和 2Otto von Guericke University Magdeburg 两所大学合作的工作,她们是项目代码的主要贡献者。
问题描述
降维技术通常用于通过投影到低维空间来降低高维数据的复杂性。但同时降维技术会带来一些问题,它会自动将数据集作为一个整体进行处理,得到整体的特征,这可能会模糊细微但相关的特征。比如,腰围与心脏风险存在关系,这是众所周知的关联特征,但是性别和抽烟也会影响心脏风险,这种隐藏特征通常很难从降维结果中获取,而且医生更加关注这些特征。
除此之外,将降维结果与原始数据连接起来进行解释是非常困难,将统计方法与用户知识进行有效整合可以更加高效的发现特征。
贡献
为了解决这些问题,这篇工作提出了 DimLift,一个通过维度捆绑进行交互式分层数据探索的工具。主要包括以下三个部分:
- 算法:通过迭代降维或用户驱动的方法生成维束(dimensional bundles)
- 维束:表示维度的组,对数据集的方差有相似的贡献
- 可视设计与交互设计:分层平行坐标图以及丰富的交互设计
- 评估:真实的临床、营养学、生态学数据
算法:生成维束
这篇工作采用的降维技术是主成分方法(Principal Component Method),由于需要分析的数据类型复杂,既有连续变量也有分类变量,采用的是 Mixed 主分析方法。为了实现简单,采用了 FAMD 方法,在实现的时候,结合了用于连续变量的主成分分析(PCA)和用于分类变量的多重对应分析(MCA),先将分类变量处理为连续变量,然后做进一步的统一处理。
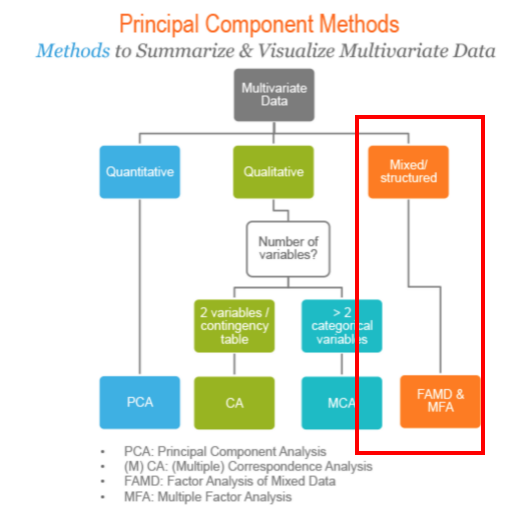
(图片来源:http://www.sthda.com/english/articles/22-principal-component-methods-videos/)
Factor analysis of mixed data (FAMD)
机制:通过识别数据变化的主要方向(称为主成分)来实现降维
本文用到的计算量:
- 方差 variance
- 特征值 eigenvalue
- 贡献 contribution:变量对主成分的贡献
- 成分负荷 loading:指观测变量与主成分的相关系数
- 贡献阈值 threshold = 1 /长度(变量),贡献大于此阈值的变量可以被认为对该主成分的贡献很重要。
更多详细参数可以查阅博客:Principal Component Methods in R 教程
生成维束
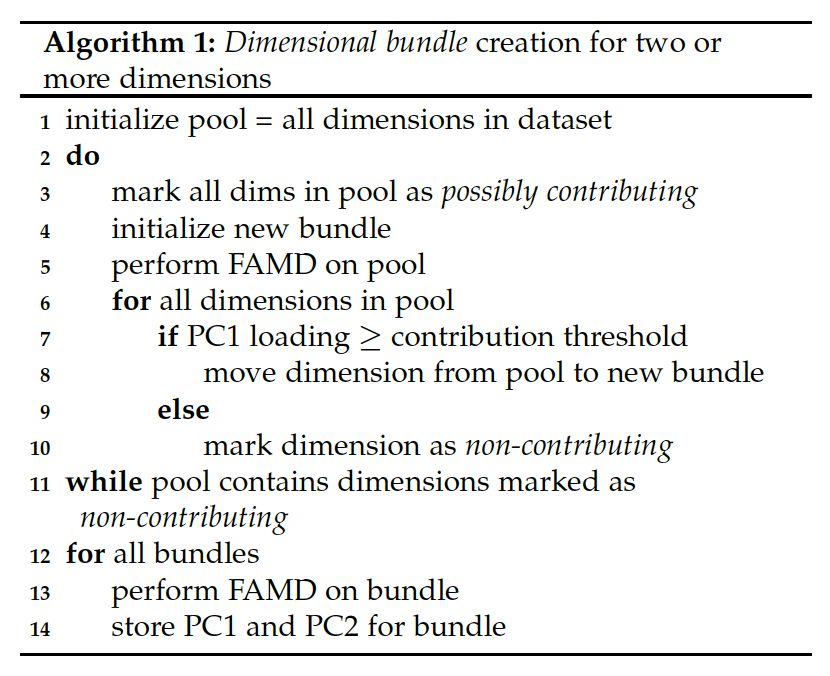
初始化一个包含所有维度的池。
循环执行:将池中所有维度标记为 possibly contributing,初始化一个新的 bundle,对池中所有的维度执行 FAMD,可以得到 PC1 loading、contribution threshold 等计算量,接下来进行判断,如果 PC1 loading >= contribution threshold,即这个维度具有较高的相关,贡献较大,则把它从池中移动到 bundle 中,否则将其标记为 non-contributing。这个循环的停止条件是池中没有表示为 non-contributing 的维度 或者 剩余维度的特征值小于 1(文中有介绍,伪代码中没有体现)。至此,bundle 就分好了。
遍历所有的 bundle,对每一个 bundle 执行 FAMD,得到一系列的计算量并储存。

可视设计与交互设计
可视编码
设计需求
- R1 支持维束的创建
- R2 支持对维束的迭代修改
- R3 允许快速检索给定维束中的项目值
- R4 将维束中感兴趣的目标维度提出来
- R5 提供有关每个维束的质量的信息
- R6 允许在维束和输入维度之间进行关联探索
编码设计
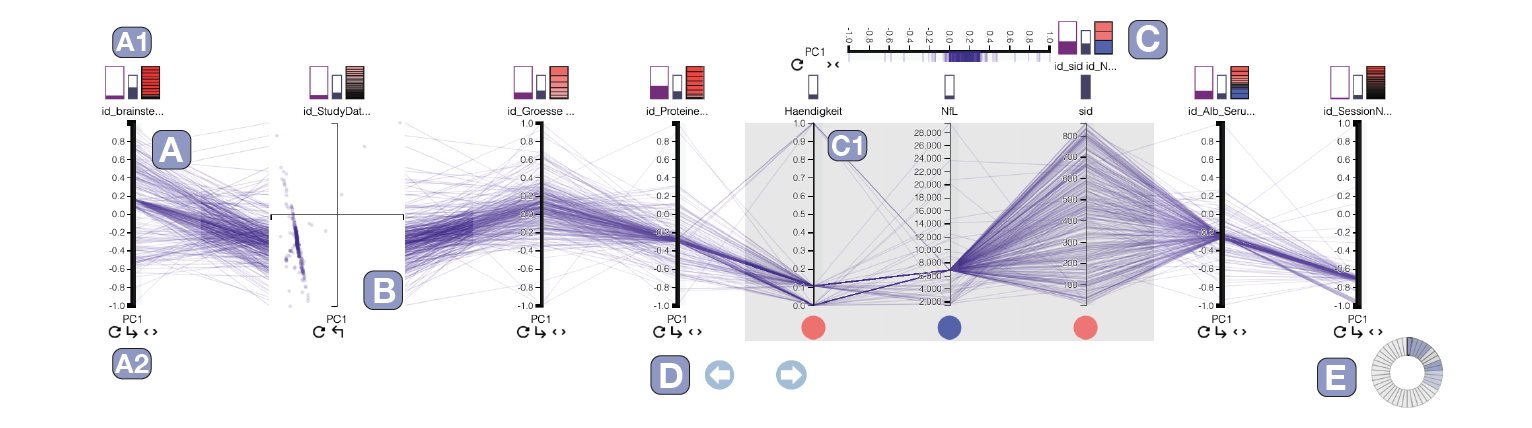
平行坐标图的轴:维束,宽度编码所包含的维度数量
一个维束包含两个 PC和原始维度。
- A:PC1 在图中均表示为主轴,item 按特征值绘制
- B:PC2 随需提供,作为从主轴水平扩展的从轴。散点图显示 PC1 和 PC2 的 item 特征值,展示相似性(展开查看两个 PC)
- C:嵌套平行坐标,展示维束的主要成分的所有维度,并绘制原始 item 值(展开查看原始维度)
- D:交互按钮
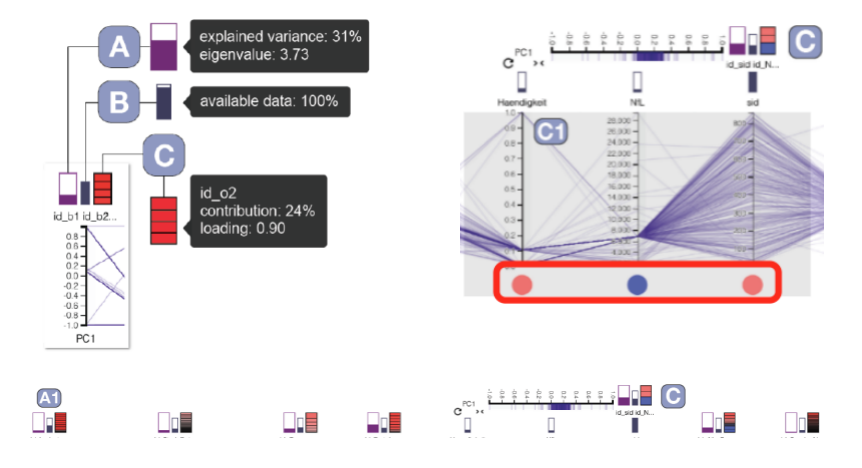
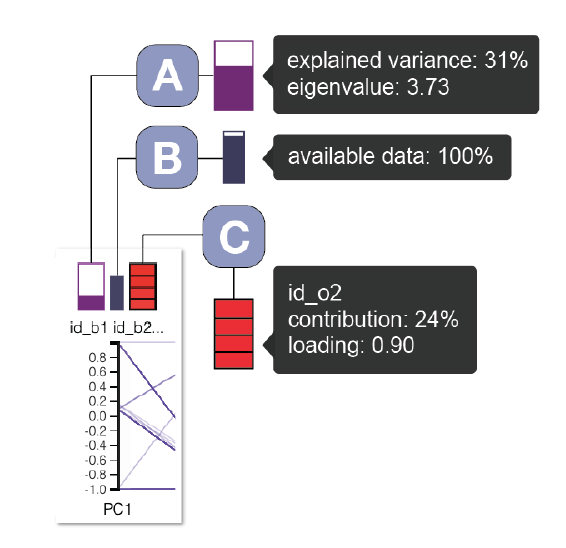
提供有关维束组成和方差贡献的信息
- A:特征值和解释方差,确定对应维束解释数据集属性的能力
- B:可用的数据
- C:所包含维度的贡献值和负荷值(相关性),通过每个维度的方差贡献分为多个部分,使用红蓝色图对相关方向进行编码,红色表示正相关,而蓝色表示负相关。展开维束嵌套,使用圆形编码。
交互设计
- Pan
- Brush & Subset
- drill down:
由于一个维束包含两个 PC和原始维度,drill down 对应的分为两种,分别是展开 PC 和展开原始维度。 - Swap:
交换 PC1 和 PC2,查看隐藏的 pattern - 创建一个新的维束
- 添加和删除维束
具体演示可查看视频 demo
评估
案例分析
数据集:Cerebral Small Vessel Disease
数据描述:
- 临床常规中收集的 307 名患者
- 数据是混合的,由 168 个维度组成,包含人口统计,实验室,教育和生活方式信息。
- 另外的 24 个维度描述了从 T1 加权磁共振成像数据得出的 24 个大脑结构体积。
- 并非所有患者都需要相同的测试和其他标准,因此缺少 76%的条目。
用户:专家
形式:think-aloud + interview
具体探索过程可查看视频 demo
专家反馈
- 系统第一印象比较复杂,但是 10 分钟后就可以独立操作。
- SPSS 是更直接,更有针对性的分析方法,而 DimLift 则采用了更加开放,面向发现的方法。 如果已经确定了目标变量并希望执行特定的目标变量,则可能不需要使用 DimLift。
- 开放式探索使用 Dimlift 会更加高效、易用。
- Dimlift 对于生成假设特别有用,并建议在临床研究中使用它。
✉️ zjuvis@cad.zju.edu.cn